1. Descriptive analytics tells you what occured in the past.
설명적 분석은 과거에 일어났던 일들에 대해 분석하는 것
2. 정규화는 데이터 중복을 줄이고 데이터 무결성을 향상시킨다. 또한 데이터 테이블 사이의 관계를 늘린다.
데이터 무결성 : 데이터가 어느 시점에서든 정확하고 완전하고 일관성이 있다는 것을 보장
3. ETL 프로세스(추출, 로드, 변환)는 대상 데이터 저장소에 로드되기 전에 완전히 처리된 데이터를 필요로 한다.
4. 일괄 처리 프로세스는 지연이 예상됩니다.
5. 오디오 파일 필사는 cognitive analytics (인지 분석)의 예시이다.
6. 왜 지난달 매출이 올랐나? -> Diagnostic (진단적 분석)
다양한 재고 항목을 사기 위해 어떻게 예산을 할당해야 하는가? -> Prescriptive (처방적 분석)
회사 사업 문서에 어떤 사람들이 언급되었는가? -> Descriptive (설명적 분석)
Descriptive : What's happening? Diagnostic : Why's happening?
Predictive : What will happen? Prescriptive : What actions should we take?
7. 스타 스키마는 정규화되지 않았고 눈송이 스키마는 정규화되었다.
Fact table : 중앙에 집중되어있는 테이블, Dimension table : 여러개로 뻗어있는 차원 테이블
8. Azure Synapse Analytics의 대규모 병렬 처리 엔진은 컴퓨팅 노드 전반에 걸쳐 처리를 분산한다.
9. 클러스터형 인덱스 : 키 값을 기준으로 테이블의 데이터 행을 정렬하고 저장하는 테이블과 연결된 개체
10. 관계형 데이터베이스는 대량의 트랜잭션 쓰기를 포함하는 시나리오에 적합하다.
관계형 데이터베이스는 쓰기에 최적화되어 있다.
11. ELT 프로세스에서 추출은 CRM 시스템, 로드는 데이터 웨어하우스, 변환은 메모리 내 데이터 통합 도구를
통해 실행한다.
12. 스캐터 : 두 숫자 사이의 관계를 보여주는 차트
Key influencer : 선택된 결과나 가치의 주요인을 보여주는 차트
트리맵 : 직사각형의 크기와 색깔을 통해 각각의 데이터를 보여주는 차트
13. Azure Storage 계정을 만들때 계정의 데이터가 Azure 지역 외부로 자동 복제되어야한다고 하면
저장소 계정에 사용할 수 있는 두 가지 복제 유형은
지리적 중복 저장소 (GRS), 읽기 액세스 지리적 중복 저장소 (RA-GRS)이다.
14. PaaS는 IaaS에 비해 셋업과 구성에 대한 노력이 적게 든다.
PaaS는 사용자에게 시스템 버전을 컨트롤하거나 업데이트하는 권한을 주지는 않는다.
PaaS는 일시정지로 인한 비용절감이 불가능하다.
15. DML의 예시 : INSERT, UPDATE, DELETE, SELECT, MERGE (각각의 데이터 실행)
DDL의 예시 : REVOKE, DISABLE, GRANT (데이터베이스의 구조를 정의)
16. 고객 데이터와 주문 데이터를 결합하는 SQL 쿼리가 있습니다. 다른 사용자가 동일한 SQL 쿼리를
다시 실행할 수 있는 데이터베이스 객체를 만들때 필요한 것은 view(뷰)입니다.
뷰는 본질적으로 SQL 쿼리의 결과 집합을 기반으로 하는 가상테이블인 데이터베이스 객체이다.
뷰에 액세스할 수 있는 권한이 있는 사용자는 테이블에서 데이터를 검색하는 것과 같은 방식으로
뷰에서 데이터를 검색할 수 있습니다.
17. 키/값 저장소는 단순한 보기에 최적화되어 있다.
18. 실시간 데이터 프로세싱은 대기 시간이 적고 데이터 생성 즉시 프로세싱된다.
19. Azure Machine Learning에서 데이터에 액세스할 수 있으려면 Azure 데이터 저장소의 경로나
공개 웹 URL에서 데이터 세트를 만들어야 한다.
파이프라인은 하나의 작업을 함께 수행하는 활동의 논리적 그룹이다.
20. ALTER : 컬럼을 추가, 삭제하거나 속성을 변경하는 구문이다.
21. 그래프 데이터베이스는 엔티티 사이의 관계 분석을 지원한다.
22. Azure Data Lake Storage는 ACL에 대한 기본 지원을 제공한다.
23. 관계형 데이터는 행과 열을 가진 테이블 형식에 저장된다.
24. 클러스터 인덱스는 지정된 열의 값을 기준으로 테이블의 데이터를 물리적으로 정렬합니다.
25. 저장된 프로시저는 데이터베이스에서 실행되는 코드블록이다.
26. 뷰는 쿼리에 의해 정의된 컨텐츠를 제공합니다.
27. Azure Database for PostgreSQL은 Microsoft Azure에서 제공하는 PaaS제품이다.
28. 관계형 데이터는 키를 사용하여 서로 다른 테이블 간의 관계를 강화합니다.
29. 지속적인 유지 관리를 최소화하면서 관계형 데이터베이스를 구현하는데 가장 적합한 서비스는
Azure SQL Database이다.
30. Index : 데이터 검색 속도를 향상시켜주는 객체, Table : 데이터를 저장하는 객체
View : 쿼리에 의해 내용이 정의되는 객체
31. 트랜잭션은 데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위 혹은 데이터베이스 시스템에서 복구 및 병행 수행시 처리되는 작업의 논리적 단위이다
32. 반복 가능한 방식으로 Azure 리소스의 상호 종속 그룹 생성을 자동화할때 Azure Resource Manager을 사용한다.
33. 데이터베이스 수준 방화벽으로 인해 IP주소 변경 후 데이터 접근에 제한이 생길 수 있다.
34. SQL Server Management Studio(SSMS)는 SQL Server에서 Azure SQL Database에 이르기까지
모든 SQL 인프라를 관리하기 위한 통합 환경이다.
Visual Studio Code는 디버깅, 작업 실행, 버전 제어와 같은 개발 작업을 지원하는 간소화된 코드 편집기이다.
Azure Data Studio는 여러 탭 창, 풍부한 기능 등의 기본 제공 기능으로 일상 업무를 보다 쉽게 만들어주는 최신 키보드 중심 SQL 코딩 환경을 제공한다.
SQL Server Data Tools(SSDT)는 SQL Server 관계형 데이터베이스, Azure SQL 데이터베이스, Analysis Services(AS) 데이터 모델, Integration Services(IS) 패키지, Reporting Services(RS) 보고서를 빌드하기 위한 최신 개발 도구이다.
35. sqlcmd 유틸리티를 사용하면 명령 프롬프트에서 Transact-SQL문, 시스템 프로시저 및 스크립트 파일을 입력할 수 있다.
36. SQL Server Management Studio는 SQL 노트북을 만드는 것이 아니라 Microsoft SQL Server 내의 모든 구성 요소를 구성, 관리 및 운영하기 위한 것입니다. 대신 Azure Data Studio를 사용하여 SQL 노트북을 만들 수 있다.
37. PaaS의 이점 : 최신 기능에 대한 액세스, 서버 인프라 관리를 위한 관리 노력 감소
38. 논리 서버의 서버 관리자 로그인 계정으로 Azure SQL 데이터베이스에 항상 연결할 수 있다.
39. Azure Data Studio는 Windows, macOS, Linux에서 클라우드 데이터 플랫폼을 사용하는 데이터 전문가를 위한 크로스 플랫폼 데이터베이스 도구입니다.
40. TDE는 저장 중인 데이터를 보호하기 위해 데이터베이스를 암호화합니다.
41. 다중 요소 인증(MFA)은 사용자가 리소스나 애플리케이션에 액세스하기 위해 두 가지 이상의 인증 형식을 제공하도록 요구하는 추가 인증 계층을 추가하는 보안 기능입니다.
Azure AD 인증은 MFA를 지원하지만 서비스 주체인증, SQL 인증, 인증서 인증은 MFA를 지원하지 않는다.
42. 기본적으로 각 Azure SQL 데이터베이스는 서버 수준 방화벽으로 보호됩니다.
43. Microsoft SQL Server Data Tools(SSDT)는 프로젝트 지향 오프라인 데이터베이스 개발을 지원하는 그래픽 도구입니다. 이를 통해 개발자는 Visual Studio 내에서 SQL Server 데이터베이스를 설계, 개발 및 배포할 수 있습니다.
Microsoft SQL Server Management Studio(SSMS)는 SQL Server 데이터베이스를 관리하기 위한 그래픽 도구입니다.
주로 보안 관리, 백업 및 성능 튜닝과 같은 관리 작업에 중점을 둡니다.
Azure Databricks는 클라우드 기반 빅데이터 처리 및 분석 플랫폼입니다. 데이터베이스 디자인 도구가 아닙니다.
Azure Data Studio는 온프레미스 및 클라우드 기반 데이터베이스에서 작업하기 위한 크로스 플랫폼 데이터베이스 관리 도구입니다. 주로 쿼리, 스크립팅 및 디버깅과 같은 관리 작업에 중점을 둡니다.
44. 강력한 일관성 보장이 필요한 경우에는 관계형 데이터베이스를 사용해야 합니다.
45. 관계형 데이터는 테이블들의 관계를 강화하기 위해 키를 사용한다.
46. Azure Private Link는 Azure 가상 머신이 데이터베이스를 인터넷에 노출시키지 않고도 Azure SQL 데이터베이스에 연결할 수 있도록 해준다.
47. Azure Cosmos DB 계정을 만들 때 데이터베이스 작업에 사용할 API를 선택해야 하고 계정 생성 중에 API를 선택하면 변경할 수 없습니다.
48. Azure Data Lake Storage - RBAC
49. 보관 계층은 대량의 데이터를 저장하도록 최적화되었으며 다른 계층에 비해 가장 낮은 스토리지 비용을 제공합니다.
Cool 계층의 검색 시간은 보관 계층보다 빠르며 분 단위로 측정되지만 저장 비용은 보관 계층보다 높습니다.
Hot 계층의 저장 비용은 세 계층 중 가장 높지만 밀리초 또는 초 단위로 측정되는 가장 빠른 검색 시간을 제공합니다.
50. Gremlin API - 그래프 데이터, MongoDB API - Json 문서, Table API - 키/값 데이터
51. 가용성 영역 - 지역 내 중복성 제공, 다중 마스터 모델 - 모든 지역에서 데이터를 쓰고 읽는 기능
강력한 일관성 수준 - 모든 읽기 작업이 가장 최근의 쓰기를 수신하도록 보장하는 기능
자동 장애 조치 - 기본 지역에서 장애가 발생할 경우 읽기 및 쓰기 작업을 보조 지역으로 자동으로 전환하는 기능
52. Azure Cosmos DB API는 다중 마스터 모델을 지원하지만 Azure Table Storage는 그렇지 않다.
53. Azure Cosmos DB의 SQL(Core) API에서 항목은 JSON으로 저장됩니다.
Azure Files는 SMB 프로토콜을 기반으로 하는 기본 클라우드 파일 공유 서비스를 제공합니다.
54. 같은 Azure Storage 계정으로 blob, table, file storage를 모두 사용할 수 있다.
Azure Storage 계정으로 Azure Data Lake Storage를 구현할 수 있다.
55. 데이터베이스 수준과 컨테이너 수준에서 Azure Cosmos DB 처리량을 설정할 수 있다.
56. PolyBase는 Transact-SQL 쿼리를 사용하여 Azure Blob 저장소에서 데이터를 검색하는 Azure Synapse Analytics 기능입니다.
57. 파이프라인 실행을 시작하려면 트리거를 정의해야 합니다. 트리거는 파이프라인을 언제, 얼마나 자주 실행해야 하는지 정의하는 Azure Data Factory의 구성 요소입니다.
58. OLTP(온라인 트랜잭션 처리) 워크로드는 데이터베이스 삽입, 업데이트, 삭제와 같은 대량의 짧고 빠른 트랜잭션이 특징인 워크로드 유형입니다.
59. 드릴 다운은 Power BI 보고서의 기능으로, 데이터를 더 자세히 탐색할 수 있습니다.
Power BI의 데이터 흐름은 데이터 세트에 로드되기 전에 데이터를 변환하고 준비하는 데 사용됩니다.
Microsoft Power Apps는 사용자 지정 비즈니스 애플리케이션을 만들 수 있는 별도의 도구입니다.
60. Apache Spark 클러스터를 프로비저닝하는 데 사용할 수 있는 두 가지 Azure 서비스는 Azure HDInsight와 Azure Databricks입니다.
61. IR(Integration Runtime)은 Azure Data Factory에서 다양한 네트워크 환경에서 데이터 통합 기능을 제공하는 데 사용되는 컴퓨팅 인프라입니다.
62. Power BI의 페이지 매김 보고서는 이제 사용자가 PDF 및 Word 파일과 같이 인쇄 및 보관에 최적화된 고정 레이아웃 문서를 생성할 수 있도록 합니다.
63. 데이터 웨어하우스의 주 목적은 여러 소스의 데이터에 의존하는 복잡한 쿼리에 대한 답변을 제공합니다.
64.
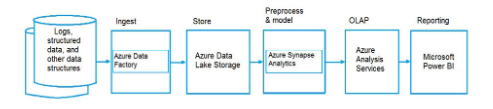
65. Azure Synapse Analytics - 시스템의 데이터와 독립적으로 컴퓨팅을 확장할 수 있고 일시중지를 통해 비용을 줄일 수 있다. 그리고 용량이 초과하면 자동으로 용량을 늘린다.
66. 스트리밍 데이터는 가장 최근에 수신된 데이터 또는 특정 기간 내의 데이터에 액세스할 수 있습니다.
67. Synapse Link는 클라우드 기반 하이브리드 트랜잭션 및 분석 처리(HTAP) 기능으로, 별도의 분석 저장소에 데이터를 추출, 변환 및 로드(ETL)할 필요 없이 Azure Cosmos DB에서 운영 데이터에 대한 거의 실시간 분석을 실행할 수 있습니다.